
Loading Runtime
Clustering in machine learning is a technique used to group similar data points together based on certain characteristics or features. The goal of clustering is to identify natural groupings in the data without any prior knowledge of the group memberships. In other words, it is an unsupervised learning approach where the algorithm tries to find patterns and structures within the data without explicit guidance on what those patterns should be.
The process of clustering involves assigning data points into clusters in such a way that data points within the same cluster are more similar to each other than to those in other clusters. The similarity between data points is typically determined using distance or similarity measures.
There are various clustering algorithms, each with its own approach to defining and forming clusters. Some commonly used clustering algorithms include:
- K-Means Clustering: This algorithm partitions the data into k clusters by iteratively assigning data points to the nearest cluster center and updating the center based on the mean of the assigned points.
- Hierarchical Clustering: This method builds a hierarchy of clusters, starting with individual data points and merging them into larger clusters based on their similarities. It can result in a tree-like structure called a dendrogram.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): DBSCAN groups together data points that are close to each other and have a sufficient number of neighbors, while marking isolated data points as outliers.
- Agglomerative Clustering: Similar to hierarchical clustering, agglomerative clustering starts with individual data points and progressively merges them into larger clusters based on a linkage criterion.
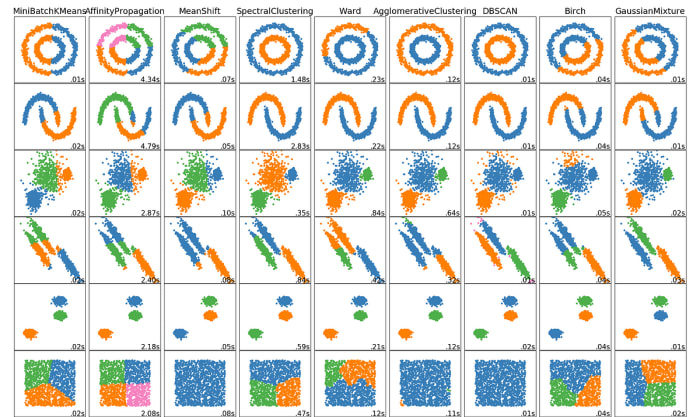
Clustering is widely used in various applications, such as customer segmentation, anomaly detection, image segmentation, and document categorization. The choice of a clustering algorithm depends on the characteristics of the data and the specific goals of the analysis.